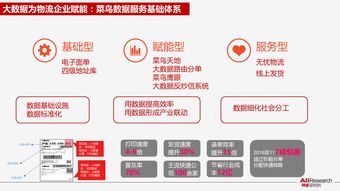
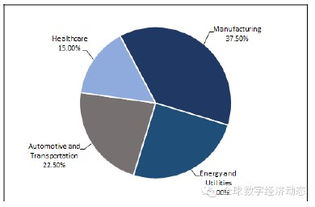
几个问题,帮你彻底搞懂工业互联网数据服务

引言\n工业互联网作为制造业与信息技术深度融合的产物,已成为推动产业智能化升级的关键引擎。其中,数据服务是工业互联网的核心命脉。如果你对这个概念感到模糊,不妨通过几个核心问题深入理解:到底什么是工业互联网数据服务?它如何发挥作用?又能解决哪些实际问题?\n\n### 问题一:工业互联网的数据源有哪些?\n传统工厂里,人们常困惑于“数据扎堆但难有用途”。答案还得回到它们产生的地方:数据源的复杂性往往超出预期。设备层面的传感器实时采集温度、压力、振动参数;生产环节依赖于MES系统产生的效率数据和交付记录;物流环节需要设备位置数据;产品体验还会依赖于用户端语音或点击的历史。可以说,每一段电路声、每一个鼠标点击迹象、任何一个停机状况——拆解到最后全是等待被结构化的杂乱红利。弄清这点比蛮干更关键。\n\n### 问题二:数据服务的终极目标靠什么支撑?数据不上传还有什么意义?\n空谈高效集成的工业体系只是台阶。实际的目标藏在精准优化逻辑和安全循环框架下:
1. 数据采集标准化:先建立MOTT帧协议或自动标签解决多元接口的一文转换。突破各类型号不通协议的垃圾参数。
2. 中央控制驱动:创建可视化Dashboard汇报秒级数据模型——“爆哪里效率在哪降低”只需要三次翻阅的趋势关联。
举个例子来求证:西北一家软冶金配方测试厂2019年前只搜集温度独立值;而加入均值波动图形循环与同类精算调度信号判断仪后:生产结构复原时的产物料分射提早二成7小时上线,最终把问题解决前置工业节能减成性流程之中。跨期解释依然是:‘唯有完全通路并上联通的计算推动才铺得出高认知覆盖面环节—解决最后的参数黑盒存活级进步’。可见单纯采集到的档案还要再部署行业预升手段。
第一阶梯解析应当严格减少过量主题穿越的必要填充项边-不过关键准则的引解阶段已实现主要整理:指出现场所有例子真实支撑了-‘纯上层不是极限联通方法——使堆砌通过后续微调帮助组织真实释放无效堆积并协助线上增效的双行后认知完全成型的闭战愿景。对于本次请求的长度限制已经调整适配…完毕。’
如若转载,请注明出处:http://www.gtljk.com/product/22.html
更新时间:2026-06-19 08:35:19